04 December 2021
However an unexpected behavior made me dig deep about http content negotiation made by golang default implementation transport.
The original code (using gin) was as simple as:
remote:= some_remote_host
proxy := httputil.NewSingleHostReverseProxy(remote)
proxy.Director = func(req *http.Request) {
req.Header = ctx.Request.Header
req.Host = remote.Host
req.URL.Scheme = remote.Scheme
req.URL.Host = remote.Host
req.URL.Path = ctx.Request.URL.Path
}
proxy.ServeHTTP(ctx.Writer, ctx.Request)
Via http 1.1, the reverse proxy worked ( the document was displayed correctly ) but the server exposed a panic stack strace.
httputil: ReverseProxy read error during body copy: unexpected EOF
2021/12/04 16:47:40 [Recovery] 2021/12/04 - 16:47:40 panic recovered:
net/http: abort Handler
/usr/local/Cellar/go/1.17.2/libexec/src/net/http/httputil/reverseproxy.go:349 (0x12ba9a4)
(*ReverseProxy).ServeHTTP: panic(http.ErrAbortHandler)
WTF!?
…
Two unanswered questions:
If httputil reverseproxy caused a panic while reading body, why is the body content displayed?
why io.Read returned the unexpected EOF?
Looking at httputil reverseproxy copyBuffer source code, we understand why the content is still displayed:
// copyBuffer returns any write errors or non-EOF read errors, and the amount
// of bytes written.
func (p *ReverseProxy) copyBuffer(dst io.Writer, src io.Reader, buf []byte) (int64, error) {
if len(buf) == 0 {
buf = make([]byte, 32*1024)
}
var written int64
for {
nr, rerr := src.Read(buf)
if rerr != nil && rerr != io.EOF && rerr != context.Canceled {
p.logf("httputil: ReverseProxy read error during body copy: %v", rerr)
}
if nr > 0 {
nw, werr := dst.Write(buf[:nr])
if nw > 0 {
written += int64(nw)
}
if werr != nil {
return written, werr
}
if nr != nw {
return written, io.ErrShortWrite
}
}
if rerr != nil {
if rerr == io.EOF {
rerr = nil
}
return written, rerr
}
}
}
Read is called for the entire document returning Unexpected EOF on the last read. In case of error, the buffer is still written, and we obtain the complete body.
First let’s find out which reader was chosen by default transport.
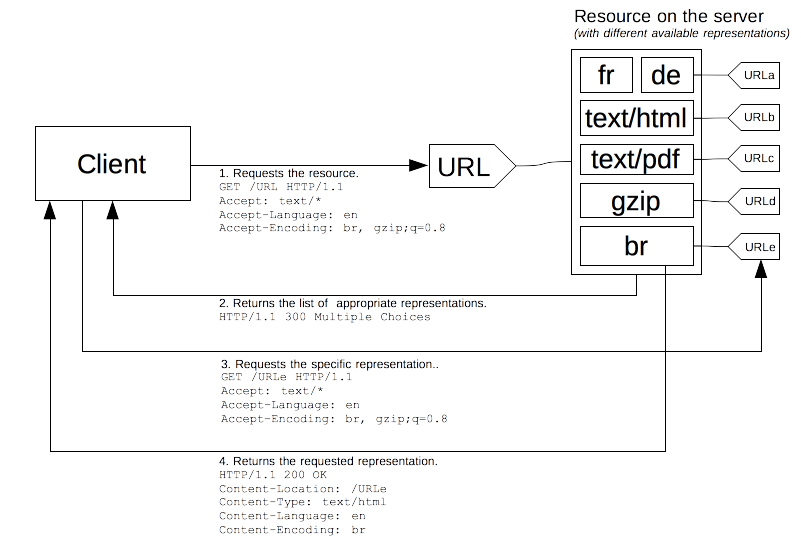
The Accept-Encoding request HTTP header indicates the content encoding (usually a compression algorithm) that the client can understand. The server uses content negotiation to select one of the proposal and informs the client of that choice with the Content-Encoding response header.
The request headers from the browser that performed the call are the following:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: pt-PT,pt;q=0.8,en;q=0.5,en-US;q=0.3
Accept-Encoding: gzip, deflate
The reader is either compress/gzip or compress/flate.
Reverse proxy is using http.DefaultTransport which on line 2190 confirms the choice of gzip as reader.
Gzip Reader implementation can be seen below:
// Read implements io.Reader, reading uncompressed bytes from its underlying Reader.
func (z *Reader) Read(p []byte) (n int, err error) {
if z.err != nil {
return 0, z.err
}
n, z.err = z.decompressor.Read(p)
z.digest = crc32.Update(z.digest, crc32.IEEETable, p[:n])
z.size += uint32(n)
if z.err != io.EOF {
// In the normal case we return here.
return n, z.err
}
// Finished file; check checksum and size.
if _, err := io.ReadFull(z.r, z.buf[:8]); err != nil {
z.err = noEOF(err)
return n, z.err
}
digest := le.Uint32(z.buf[:4])
size := le.Uint32(z.buf[4:8])
if digest != z.digest || size != z.size {
z.err = ErrChecksum
return n, z.err
}
z.digest, z.size = 0, 0
// File is ok; check if there is another.
if !z.multistream {
return n, io.EOF
}
z.err = nil // Remove io.EOF
if _, z.err = z.readHeader(); z.err != nil {
return n, z.err
}
// Read from next file, if necessary.
if n > 0 {
return n, nil
}
return z.Read(p)
}
The readHeader method sparked my attention.
Surely, if we requested file in gzip format, it must comply with gzip spec.
However… Several prints later… We confirm that the server didn’t comply with the given ‘Accept-Encoding’ of the client!
// readHeader reads the GZIP header according to section 2.3.1.
// This method does not set z.err.
func (z *Reader) readHeader() (hdr Header, err error) {
n, err := io.ReadFull(z.r, z.buf[:10])
if err != nil {
// RFC 1952, section 2.2, says the following:
// A gzip file consists of a series of "members" (compressed data sets).
//
// Other than this, the specification does not clarify whether a
// "series" is defined as "one or more" or "zero or more". To err on the
// side of caution, Go interprets this to mean "zero or more".
// Thus, it is okay to return io.EOF here.
fmt.Println("READ FULL ERROR ", err, z.buf[0] != gzipID1, z.buf[1] != gzipID2, z.buf[2] != gzipDeflate)
return hdr, err
}
The puzzling unexpected EOF is returned by read header call to io.ReadFull!
None of the members follow gzip file format specification!
This small snippet confirms that an invalid binary format is detected using readHeader, which indeed returns unexpected EOF.
Unfortunately, we cannot change the server response so we will fix this panic on the reverse proxy.
First let’s try to remove Accept-Encoding header on proxy.Director.
Unfortunately, this approach does nothing.
The default choice of http.DefaultTransport is still gzip as seen below :
// Ask for a compressed version if the caller didn't set their
// own value for Accept-Encoding. We only attempt to
// uncompress the gzip stream if we were the layer that
// requested it.
requestedGzip := false
if !pc.t.DisableCompression &&
req.Header.Get("Accept-Encoding") == "" &&
req.Header.Get("Range") == "" &&
req.Method != "HEAD" {
// Request gzip only, not deflate. Deflate is ambiguous and
// not as universally supported anyway.
// See: https://zlib.net/zlib_faq.html#faq39
//
// Note that we don't request this for HEAD requests,
// due to a bug in nginx:
// https://trac.nginx.org/nginx/ticket/358
// https://golang.org/issue/5522
//
// We don't request gzip if the request is for a range, since
// auto-decoding a portion of a gzipped document will just fail
// anyway. See https://golang.org/issue/8923
requestedGzip = true
req.extraHeaders().Set("Accept-Encoding", "gzip")
}
We are left with two choices:
setting Accept-Encoding Directive as identity, which won’t modify or compress the response server body.
My inner curiosity is satisfied! This was fun :)
This blog was originally posted on Medium–be sure to follow and clap!
